Organized by:
- Fabricio Olivetti de Franca (folivetti@ufabc.edu.br, Federal University of ABC, Santo André, Brazil)
- Karine Miras (karine.smiras@gmail.com, Vrije Universiteit, Amsterdam, Netherlands)
- Denis Fantinato (Federal University of ABC, Santo André, Brazil)
- Patricia A. Vargas (Heriot-Watt University, Edinburgh, UK)
- A.E. Eiben. (Vrije Universiteit, Amsterdam, Netherlands)
Prizes:
- The 1st place will receive a US$500.00 prize sponsored by IEEE CIS*.
- The 2nd place will receive a Megaman collectible.

- The 3rd place will receive a Megaman keychain.

Extended deadline: June 15th, 23:59 (GMT).
Introduction
EvoMan [1] is a framework for testing competitive game-playing agents in a number of distinct challenges such as:
- Learning how to win a match against a single enemy
- Generalizing the agent to win the matches against the entire set of enemies
- Coevolving both the agent and the enemies to create intelligent enemies with increasing difficulties.

This framework is inspired on the boss levels of the game MegaMan II [2] in which a robot with a simple arm cannon must beat more sophisticated robots (8 in total) with different powers.
Challenge
In this challenge, the contestants should train their agent on a set of four enemies (defined by the contestant) and evaluate how general is their learned strategy when fighting against the whole set of enemies.
Since each enemy behavior greatly differs from each other, the player should learn how to identify and react to general patterns like avoiding being shot or shoot at the direction of the enemy. Learning a general strategy capable of winning over the entire enemies set can be very challenging [1,3].

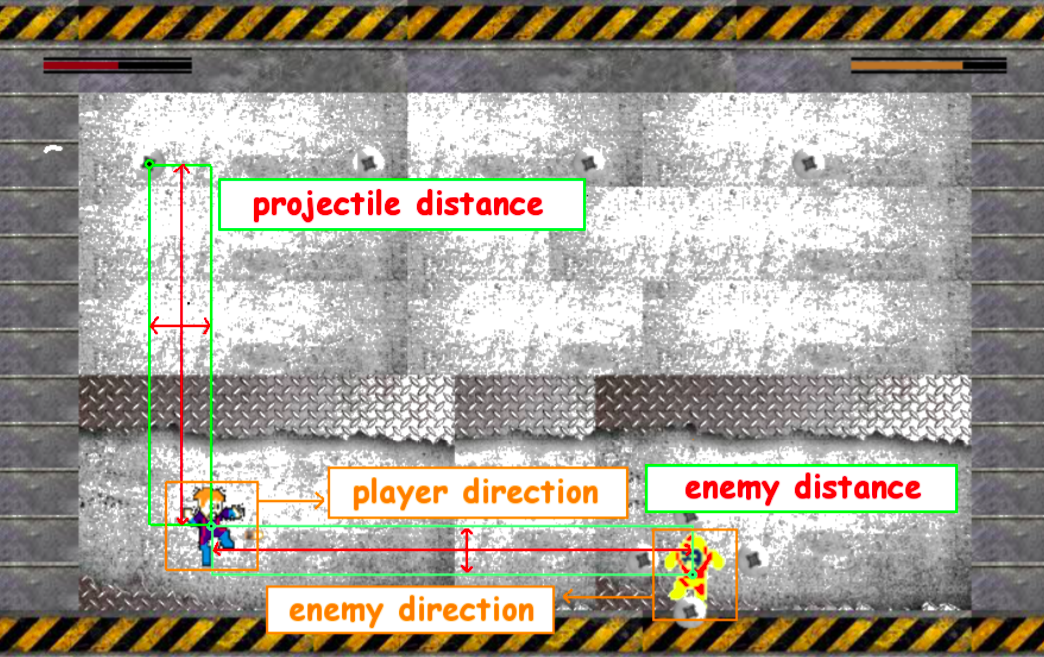
The agent will have a total of 20 sensors, with 16 of them corresponding for horizontal and vertical distance to 8 different bullets (maximum allowed), 2 to the horizontal and vertical distance to the enemy, and 2 describing the direction the player and the enemy is facing.
The framework is freely available at here and it’s compatible with Python 3.6 and 3.7 (Python 3.8 is not compatible at the moment). There is also an extensive documentation available here.
Evaluation Criteria
Both the agent and the enemies start the game with 100 energy points. Every time one player gets hit, it loses one point. Whoever reaches 0 points loses the match.
The final performance of the agent after the end of a match is calculated by the energy gain, as a maximization problem, calculated by the difference between the player and the enemy energy:
where ee, ep are the final amount of energy of the enemy and the player, respectively. The value of 100.01 is added so that the harmonic mean always produces valid results.
The main goal of this competition is that a given agent perform equally good for every boss. So, each contestant agent will be tested against all of the enemies, and they will be ranked by the harmonic mean of the performance over the different bosses.
Submission deadline
All submissions should be sent until June 15th, 23:59 (GMT).
Installing the framework
The initial code, manual and every other resources needed are available at this Github repository. The competitors should pay attention to the following directions:
- follow the installation instructions in the file evoman1.0-doc.pdf
- run the demo script controller_specialist_demo.py to test if the framework is working
- play the game using your own keyboard to understand the difficulties of the problem. Use the script human_demo.py.
The agent should be trained using the Individual Evolution and Multi-objective modes with the goal of beating each one of the four adversaries chosen for training.
Submission instructions
As a competitor, you should submit your code via GitHub Classroom, following the instructions at the https://classroom.github.com/g/YEQprX27, additionally, you should also submit a paper following the same template as used on WCCI describing your solution to the problem.
The paper should report the chosen bosses for training, the values of the average player energy (ep) and enemy energy (ee) obtained by your best agent for each one of the eight bosses and the average duration of the match (this will be used in case of a drawn).
- A competitor is NOT allowed to change the core of the framework (evoman folder).
- A competitor is NOT allowed to change the default parameters
levelandcontacthurtofEnvironmentclass.
A short paper describing a baseline for Individual mode can be found at https://arxiv.org/abs/1912.10445, this baseline can serve as an upper bound.
@misc{franca2019evoman,
title={EvoMan: Game-playing Competition},
author={Fabricio Olivetti de Franca and Denis Fantinato and Karine Miras
and A. E. Eiben and Patricia A. Vargas},
year={2019},
eprint={1912.10445},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
*IEEE CIS will contact the main leader of the winning team in order to transfer the funds.
Results
| Team | Algorithm | Enemy | ep | ee | gain |
|---|---|---|---|---|---|
| Neoman (1st place) | MLP | 1 | 64 | 0 | 164.01 |
| Fernando Ishikawa, Leandro Trovoes, Leonardo Carmo | 2 | 68 | 0 | 168.01 | |
| Federal University of ABC | 3 | 8 | 0 | 108.01 | |
| Report | 4 | 34.6 | 0 | 134.61 | |
| In the Neoman project, authors propose the extraction and selection of features and follow a neuroevolution approach, using a Multilayer Perceptron (MLP) network, adjusted by a Genetic Algorithm (GA), in order to train the agent. New features were extracted: (i) the Euclidean distance between projectiles and the agent, from vertical and horizontal distances, being the three farthest projectiles disregarded, and (ii) an indication whether or not the agent is facing the enemy, from 'directions' and 'distance to enemy'. Besides them, selected features were 'directions' and 'distance to enemy'. The two-hidden layer MLP -- with 32 and 12 neurons each layer, with sigmoid activation function -- were trained by GA, with population size of 10 along 150 generations. The agent was able to defeat all enemies. | 5 | 84.4 | 0 | 184.41 | |
| 6 | 17.8 | 0 | 117.81 | ||
| 7 | 81.4 | 0 | 181.41 | ||
| 8 | 58.6 | 0 | 158.61 | ||
| Harmonic Mean | 146.88 | ||||
| UAIC (2nd place) | PPO | 1 | 99.5 | 0 | 199.51 |
| Gabriel-Codrin Cojocaru, Sergiu-Andrei Dinu, Eugen Croitoru | 2 | 89.93 | 0 | 189.94 | |
| Faculty of Computer Science “Al. I. Cuza” University | 3 | 6.73 | 20 | 86.74 | |
| Report | 4 | 2.63 | 22.33 | 80.31 | |
| The UAIC team uses an feedforward Artificial Neural Network -- two hidden layers, with 32 neurons each, with logistic sigmoid activation function -- trained by an ensemble cascade method with two stages: the first stage involves algorithms that either found acceptable solutions quickly or had a high explorative bias, which were the Q-Learning, Genetic Algorithms (GA) and Particle Swarm Optimization (PSO) -- both GA and PSO algorithms were tested with sparse and iterative evaluations --; in the second stage, it is expected to exploit and refine the previous found solutions, being used the Proximal Policy Optimization (PPO) algorithm, being random initialization (instead of previous solutions) also considered. Changing game difficulty was also considered in learning. Besides PPO has shown to be the best first-stage algorithm, the best results were obtained with PPO randomly initialized. The best agent was able to defeat six enemies. | 5 | 57.4 | 0 | 157.41 | |
| 6 | 93.8 | 0 | 193.81 | ||
| 7 | 89.98 | 0 | 189.99 | ||
| 8 | 45.4 | 0 | 145.41 | ||
| Harmonic Mean | 138.14 | ||||
| MultiNeat (3rd place) | MultiNeat | 1 | 0 | 80 | 20.01 |
| Augusto Dantas, Aurora Pozo | 2 | 16 | 0 | 116.01 | |
| Federal University of Parana | 3 | 0 | 80 | 20.01 | |
| Report | 4 | 37 | 0 | 137.01 | |
| To evolve agents, the multiNEAT project considers the use of a cooperative coevolutionary strategy, named NeuroEvolution of Augmenting Topologies (NEAT) algorithm, in its multi-populational scheme, the multiNEAT. Basically, the algorithm starts with a set of subpopulations of minimal networks -- a feedforward neural network -- that increase in complexity over time through mutation. Each subpopulation has a NEAT instance that evolves individuals for a single enemy. The best genomes of each population are passed to a master population that evaluates the individuals for all enemies. The idea is to allow the networks to evolve in a simpler environment and make them compete in a harsher condition afterwards. The best genomes from the master population are then introduced back into the single enemy populations for the next iteration. The strategy considered subpopulation with 50 individuals, 10 migrants (individuals passed to other populations), throughout 10 subpopulations and master generations. The agent was able to beat 6 enemies out of 8, including the four enemies used for training and two other unseen enemies. | 5 | 41.2 | 0 | 141.21 | |
| 6 | 22.6 | 0 | 122.61 | ||
| 7 | 35.8 | 0 | 135.81 | ||
| 8 | 79.6 | 0 | 179.61 | ||
| Harmonic Mean | 55.54 |
References
[1] de Araújo, Karine da Silva Miras, and Fabrício Olivetti de França. “An electronic-game framework for evaluating coevolutionary algorithms.” arXiv preprint arXiv:1604.00644 (2016).
[2] M. MEGA, “Produced by capcom, distributed by capcom, 1987,” System: NES.
[3] de Araujo, Karine da Silva Miras, and Fabrício Olivetti de Franca. “Evolving a generalized strategy for an action-platformer video game framework.” 2016 IEEE Congress on Evolutionary Computation (CEC). IEEE, 2016.
[4] de Franca, F. O., Fantinato, D., Miras, K., Eiben, A. E., & Vargas, P. (2019). EvoMan: Game-playing Competition. arXiv preprint arXiv:1912.10445.
